
BigQuery MCPとは?Claude連携でSQLなしに広告データを分析する方法
「ClaudeでBigQueryのデータをそのまま分析できないだろうか」。そう考えて検索すると、出てくるのはサービスアカウントの鍵やコマンド操作の手順ばかりで、手が止まってしまった。そんな方に向けた記事です。
BigQuery MCPとは、Model Context Protocol(MCP)という共通規格を使って、ClaudeなどのAIとGoogle BigQueryを接続し、SQLを書かずに自然言語のままデータを分析できるようにする仕組みです。「先月のCPAは?」「売上が落ちた原因を調べて」と日本語で依頼するだけで、AIが裏側でクエリを組み立てて実行してくれます。
この記事では、BigQuery MCPの仕組みとできることから、サーバーの構築方式の選び方、Claudeへの接続・設定手順、そして広告データを実際にどう分析するかという実務の使い方、安全に運用するための注意点、チームで継続運用するための現実的な選択肢までを、エンジニアでない方にも分かるように一気通貫で解説します。読み終えるころには、「まず何から試し、業務にどう乗せるか」を自分で判断できる状態になります。
なお、MCPやClaude連携の全体像を先に押さえたい方は、「Claude MCPの全体像(仕組み・使い方・活用事例)」もあわせてご覧ください。
この記事でわかること
- BigQuery MCPの仕組みとできること(SQLなしで分析できる理由)
- MCPサーバーの3つの構築方式と選び方
- Claude Desktop/Codeへの接続・設定手順
- 広告データをSQLなしで深掘りする実務の使い方
- 安全に運用するための注意点(読み取り専用・最小権限・費用管理)
- チームで継続運用するための現実的な選択肢
目次
BigQuery MCPとは?仕組みを3分で理解する
結論
BigQuery MCPとは、MCP(Model Context Protocol)という共通規格でClaudeなどのAIとBigQueryをつなぎ、SQLを書かずに自然言語でデータを問い合わせ・分析できるようにする仕組みです。AIがスキーマ(テーブル構造)の確認からクエリの生成・実行までを自動で行うため、利用者はSQLを意識する必要がありません。
BigQuery MCPは、ざっくり次のような構成で動きます。
あなた(自然言語の依頼)
→ Claude(Chat / Code など)
→ BigQuery MCP(接続役のサーバー)
→ Google BigQuery(あなたのデータ)あなたが「先月の媒体別CPAを出して」と依頼すると、Claudeがその意図を解釈し、BigQuery MCPを経由してBigQueryに問い合わせ、返ってきた集計結果を分かりやすい言葉やレポートに整えて返してくれます。間にある「BigQuery MCP」が、AIとデータベースをつなぐ通訳のような役割を担っているとイメージすると分かりやすいでしょう。
そもそもMCP(Model Context Protocol)とは
MCP(Model Context Protocol)とは、AIと外部のツールやデータ(データベース、API、ファイルなど)を安全につなぐための共通規格です。これまでは「AIにこのデータを読ませたい」と思うたびに個別の連携を作る必要がありましたが、MCPという共通の作法ができたことで、対応したツールであれば同じやり方でAIにつなげられるようになりました。
BigQuery MCPは、この共通規格を「BigQueryというデータベース」に対して実装したもの、と捉えてください。MCPそのものの概念をもう少し詳しく知りたい方は、「MCP(Model Context Protocol)とは」で基礎から解説しています。
なぜBigQuery MCPだとSQLを書かなくていいのか
通常、BigQueryのデータを取り出すにはSQLというデータベース専用の言語が必要です。BigQuery MCPがSQL不要になるのは、そのSQLを書く作業をAIが肩代わりするからです。
具体的には、AIは依頼を受け取ると次のステップを自動でたどります。
- データセットやテーブルの一覧を取得する
- 対象テーブルのスキーマ(列名やデータ型)を確認する
- 依頼内容に合うSQLを生成する
- そのSQLを実行し、結果を取得する
- 結果を要約・整形して返す
利用者から見えるのは「日本語で依頼して、答えが返ってくる」という体験だけです。生成されたSQLの中身も、「使ったSQLを見せて」と頼めば確認できるため、ブラックボックスにならず、内容を検証しながら使える点も安心材料になります。
BigQuery MCPで何ができる?できること一覧
結論
BigQuery MCPを使うと、「先月のCPAは?」「売上が落ちた原因を調べて」といった自然言語の依頼だけで、データの集計・抽出・要約・グラフ用データの作成までを実行できます。SQLの知識がなくても、対話を重ねてデータを深掘りできるのが最大の価値です。
固定のダッシュボードを眺めるのではなく、思いついた問いをその場でぶつけられるのが、従来のデータ活用との一番の違いです。代表的にできることを整理すると、次のとおりです。
- 集計・KPIの確認:「先月の媒体別のクリック数とコンバージョン数」「前年同月比の売上推移」
- 原因の深掘り:「コンバージョンが落ちた週を特定して、原因になりそうな要素を挙げて」
- ドリルダウン:「数値が悪いキャンペーンを、広告グループ単位までブレイクダウンして」
- 要約・示唆出し:「この結果から言える改善ポイントを3つにまとめて」
- レポート用データの整形:「この集計を表形式にして、グラフにしやすい形で出して」
ポイントは、一度の質問で終わらず、返ってきた答えに対して「ではその要因を曜日別で見せて」と会話で掘り下げていけることです。アナリストに口頭で相談する感覚に近く、SQLや集計の待ち時間に分析の思考が途切れません。
自然言語でできる分析の具体例
イメージしやすいように、実際の依頼文に近い例を挙げます。いずれもSQLは一切書きません。
- 「2026年5月のコンバージョン数を、媒体別・週別の表で出して」
- 「先月いちばんCPAが悪化したキャンペーンを3つ、悪化幅とあわせて教えて」
- 「直近3ヶ月で、曜日と時間帯のどこにコンバージョンが集中しているかをまとめて」
- 「この結果をもとに、来月の予算配分の案を提案して」
このように、「集計してほしい」だけでなく「考えてほしい」「提案してほしい」まで地続きで頼めるのが、AIを介したデータ分析ならではの強みです。なお、BigQuery連携に限らず、手元のCSV・Excelを添付して分析する方法も含めたClaudeでのデータ分析の全体像は、「Claudeでデータ分析する方法」で解説しています。
BIツール(Looker Studio等)との違いと使い分け
「それなら今使っているBIツールと何が違うのか」と感じる方もいるでしょう。両者は競合するものではなく、役割が異なります。
| 観点 | BIツール(Looker Studio等) | BigQuery MCP(対話型分析) |
|---|---|---|
| 得意なこと | 決まった指標を毎回同じ形で見る | その場で思いついた問いを深掘りする |
| 操作 | 画面のフィルタ・期間を切り替え | 自然言語で質問・追加質問 |
| 向いている場面 | 定例レポート・モニタリング | 原因究明・アドホック分析・示唆出し |
| アウトプット | 固定のグラフ・ダッシュボード | 文章・表・レポート(柔軟に整形) |
実務では、定例で見る数字はBIツールの固定レポートで、「なぜ?」を掘る場面はBigQuery MCPの対話で、と使い分けるのが効率的です。GA4やGoogle広告などの定例レポートをまず整えたい場合は、買い切り型の「Looker Studioテンプレート」のような固定レポートの仕組みと組み合わせると、モニタリングと深掘りの両輪が回ります。
BigQuery MCPサーバーの3つの構築方式と選び方
結論
BigQuery MCPサーバーの構築方式は大きく3つあります。①OSSを自分で建てる、②GoogleのフルマネージドなリモートMCPサーバーを使う、③連携基盤の構築・運用ごと任せる、です。とりあえず試すならフルマネージド、業務に乗せて継続運用するなら基盤を任せる方式が現実的です。
「BigQuery MCPを使う」と一口に言っても、その入り口(=MCPサーバーをどう用意するか)にはいくつかの選択肢があります。まずは3方式の違いを一覧で押さえましょう。
| 方式 | 構築難易度 | 運用負荷 | カスタマイズ性 | 向いている人 |
|---|---|---|---|---|
| ①OSSを自作 | 高 | 高 | 高 | 自分で細かく制御したいエンジニア・検証目的 |
| ②フルマネージド(リモート) | 低 | 低 | 中 | まず手軽に試したい人・Google Cloud標準で揃えたい人 |
| ③連携基盤を任せる | なし(依頼のみ) | なし(保守込み) | 中〜高 | チームで継続運用したい・運用に手をかけたくない事業会社/代理店 |
それぞれの特徴を見ていきます。
①OSSを自分で構築する(@ergut/mcp-bigquery-server など)
GitHubで公開されているOSS(オープンソース)のMCPサーバーを使い、自分の環境に建てる方式です。代表的なものに @ergut/mcp-bigquery-server があり、読み取り専用でBigQueryに安全にアクセスできるよう設計されています。
npx などで手元から起動でき、無料で始められるのが魅力ですが、サービスアカウント鍵の管理、起動環境の用意、バージョンアップ対応などを自分で担う必要があります。挙動を細かく制御したいエンジニアや、まず仕組みを理解したい検証用途に向いています。
②フルマネージド(リモート)MCPサーバーを使う
Google Cloudが提供する、フルマネージドのリモートMCPサーバーを使う方式です。サーバーを自分で建てる必要がなく、用意されたエンドポイント(https://bigquery.googleapis.com/mcp)をMCPクライアント側に指定するだけで利用を開始できます。
構築・保守の手間がほとんどかからないため、「まず手軽にBigQuery MCPを試したい」「インフラはGoogle Cloud標準で揃えたい」という場合の最有力候補です。一方で、提供される機能の範囲内で使う形になるため、独自の前処理や複雑な要件を細かく作り込みたい場合は①や③の検討余地があります。
③連携基盤の構築・運用を任せる(継続運用向け)
3つ目は、Claude×BigQueryの連携基盤の構築・運用そのものを任せる方式です。サーバーの構築や権限設計、データ連携の保守といった「動かし続けるための作業」を外部に委ねつつ、自分たちは分析に集中できます。
インハウスプラスの「Claude MCP連携サービス」はこの形にあたり、広告データを対象としたClaude×BigQueryの連携基盤を構築・運用します。検証フェーズを越えて「チームで毎月安定して使いたい」段階になったときに現実的な選択肢となります。この方式の詳しい比較は「自力構築 vs 連携基盤を任せる」の章で改めて掘り下げます。
BigQuery MCPの接続・設定手順(Claude Desktop/Claude Code)
結論
最短の接続手順は4ステップです。①GCPでサービスアカウントと鍵(JSON)を用意して読み取り権限を付与、②MCPサーバーを用意(OSSまたはリモート)、③Claude Desktop/Codeの設定ファイルにMCPサーバーを登録、④Claudeから「テーブル一覧を見せて」と依頼して接続を確認、です。読み取り専用で設定するのが安全です。
ここでは、OSSの @ergut/mcp-bigquery-server をClaude Desktopにつなぐ流れを例に解説します。リモートMCPサーバーを使う場合は、後述のとおりエンドポイントを指定するだけなので、より簡単です。
事前準備(GCP・サービスアカウント・読み取り権限)
接続の前に、Google Cloud側で次の3つを用意します。
- 対象のBigQueryプロジェクト:分析したいデータが入っているプロジェクトのID(project-id)を控えます。
- サービスアカウントの作成:BigQueryにアクセスするための「鍵を持った代理ユーザー」を作ります。
- 読み取り権限の付与とJSON鍵のダウンロード:作成したサービスアカウントに、BigQueryの閲覧系の権限(データ閲覧・ジョブ実行)を付与し、認証用のJSON鍵ファイルをダウンロードして安全な場所に保管します。
安全のポイント
権限は必要最小限にとどめ、書き込み系(編集・削除)の権限は付けないのが基本です。権限とセキュリティの考え方は「BigQuery MCPを安全に運用するための注意点」の章で詳しく解説します。
Claude Desktopでの設定(claude_desktop_config.json)
Claude Desktopの設定ファイル claude_desktop_config.json を開き、MCPサーバーの定義を追記します。基本的な構造は次のとおりです。
{
"mcpServers": {
"bigquery": {
"command": "npx",
"args": [
"-y",
"@ergut/mcp-bigquery-server",
"--project-id",
"your-project-id",
"--location",
"asia-northeast1",
"--key-file",
"/path/to/service-account-key.json"
]
}
}
}--project-id:手順で控えたBigQueryのプロジェクトID--location:データセットのロケーション(東京リージョンならasia-northeast1など、実際のデータセットに合わせる)--key-file:ダウンロードしたJSON鍵ファイルへのフルパス
記述後にClaude Desktopを再起動すると、設定が読み込まれます。
Claude Code/Cursorでの設定の違い
エンジニアの方は、Claude CodeやCursorといった開発ツールからBigQuery MCPを使うこともできます。設定の考え方は同じで、「どのMCPサーバーを、どんな引数で起動するか」を各ツールの設定ファイル(MCP設定)に書く形です。
Claude CodeやCursorはターミナルやエディタと一体で動くため、生成されたSQLをその場で確認したり、分析結果を使った処理を続けて書いたりしやすいのが利点です。一方、非エンジニアの方や、まず気軽に試したい方は、画面操作で完結するClaude Desktop、あるいは前章のリモートMCPサーバーから始めると迷いにくいでしょう。
接続できないときのチェックリスト
設定後にうまくつながらない場合、つまずきやすいポイントは次のとおりです。
- 鍵ファイルのパスが違う:
--key-fileに指定したパスが実在し、フルパスになっているか - 権限が足りない:サービスアカウントにBigQueryの閲覧・ジョブ実行権限が付いているか
- ロケーションの不一致:
--locationが実際のデータセットのロケーションと合っているか - 再起動していない:設定変更後にClaude Desktop(またはツール)を再起動したか
- プロジェクトIDの誤り:
--project-idが分析対象のプロジェクトと一致しているか
接続が確認できたら、まずは「データセットの一覧を見せて」「このテーブルの列を教えて」と尋ねてみると、正しくつながっているかを安全に確かめられます。なお、こうした接続・権限・保守を自分たちで抱えたくない場合は、連携基盤ごと任せる選択肢もあります(「自力構築 vs 連携基盤を任せる」の章で解説します)。
広告運用の現場でBigQuery MCPは何ができる?──マーケター視点の実例
結論
広告データをBigQueryに集約してBigQuery MCPでClaudeにつなぐと、「先月のCPAを媒体別に出して」「悪化キャンペーンTop3と改善案を教えて」といった依頼だけで、媒体・クリエイティブ・キーワード・ユーザー属性・時間帯まで横断した分析ができます。さらに結果を、Markdown・経営会議向けのスライド(PPTX)・Slack投稿用テキストに整形するところまで一気に進められます。
ここまでは「どう接続するか」という技術の話でしたが、マーケターにとって本当に知りたいのは「自分の広告運用にどう効くのか」のはずです。この章では、インハウスプラスが提供するClaude×BigQueryの連携基盤(Claude MCP連携サービス)の実運用をもとに、広告分析の具体像を紹介します。
広告データをSQLなしで深掘りする(プロンプト例)
広告データが入ったBigQueryにつながっていれば、次のような依頼を日本語でそのまま投げられます。
- KPI分析:「先月のCPAを出して」「前年同月比のコンバージョン推移を媒体別に」「プラットフォーム別の効率を比較して」
- 異常検知・示唆出し:「悪化キャンペーンTop3と、それぞれの改善案を教えて」「P-MAXのコンバージョンが減った原因を調べて」
- ドリルダウン:「キーワード別のコンバージョンを出して」「年代×性別のCPAをまとめて」「時間帯×曜日のヒートマップにして」
- クリエイティブ示唆:「成果の良い広告見出しを抽出して」「除外候補のキーワードを挙げて」
たとえば「先月いちばん効率が悪化したキャンペーンを3つ、原因の仮説と改善案つきで」と頼めば、集計から要因の整理、打ち手の提案までを一度の対話で受け取れます。SQLを書く時間も、抽出を依頼して待つ時間もかかりません。

分析できる軸・指標・対応媒体の広さ
BigQuery MCPの分析の深さは、扱えるデータの幅で決まります。広告データを連携した場合、次のような多様な切り口で深掘りできます。
- 時間軸:日/週/月/曜日/時間帯(時間帯×曜日のヒートマップなど)
- 媒体・チャネル:媒体別に加え、検索/ディスプレイ/P-MAX/動画/ショッピング等のチャネル内訳
- 構造:アカウント/キャンペーン/広告グループの階層でのドリルダウン
- 検索・クリエイティブ:キーワード、実検索クエリ、広告見出し・説明文・ランディングページ
- ユーザー属性・配信文脈:性別/年代/地域/デバイス、プレースメント(配信面)
指標も、インプレッション・クリック・費用・コンバージョン・コンバージョン値といった基本指標から、CPA・ROAS・CPC・CTR・CVRなどの算出指標まで、前期比・前年同月比・目標比を交えて分析できます。対応する広告プラットフォームは、Google広告・Meta広告・Yahoo!広告・LINE広告・X(Twitter)広告・Microsoft広告と幅広く、媒体をまたいだ横断分析も可能です。
つまり「媒体・クリエイティブ・キーワード・ユーザー属性・時間帯まで、あらゆる切り口で広告データを深掘りできる」というのが、広告運用におけるBigQuery MCPの価値です。
分析結果をレポート化する(Markdown/PPTX/Slack)
分析して終わりではなく、そのままレポートになるのも実務での大きな利点です。同じ対話の流れで、次のような出力に整形できます。
- 週次・月次レポート:Markdown形式で要点を整理
- 経営会議向けスライド:KPI・トレンド・媒体ミックス・セグメント・改善Top3などを含む構成のPPTX
- Slack共有用テキスト:絵文字付き・短文のmrkdwn記法で、悪化サマリーやアラートを即共有
たとえば「全体KPI→媒体別→悪化Top3→改善Top3→来月の打ち手」の順でドラフトを作り、そのまま経営会議用スライドに展開する、といった一連の流れを対話だけで完結できます。「2025年4月のレポートを再生成して」のように過去月を指定して当時のデータから作り直すことも可能です。
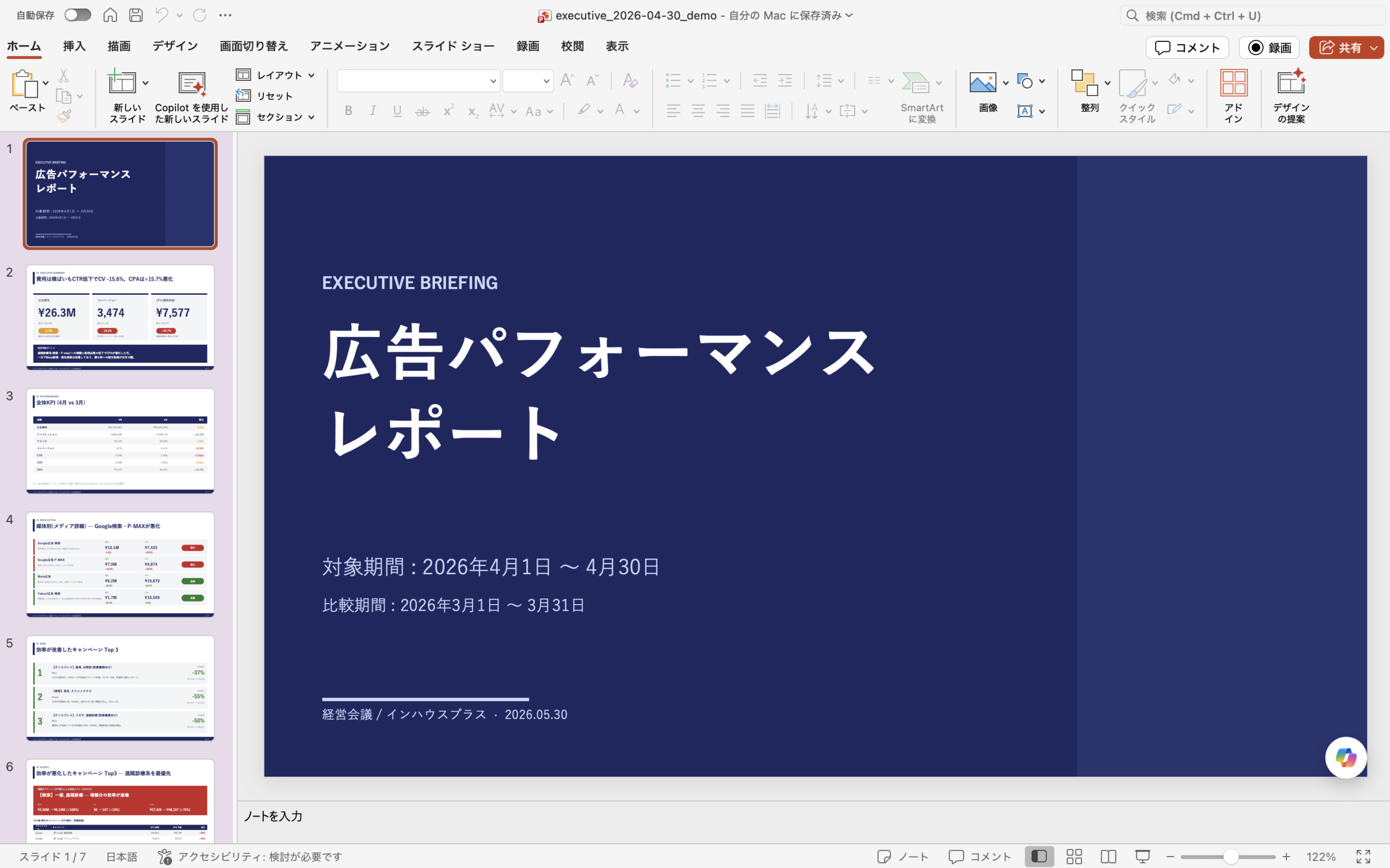
なお、インハウスプラスが提供するのは、こうした分析を行うためのClaude×BigQueryの連携基盤(接続・MCPサーバー・データ連携)の構築・運用までです。連携後の分析や資料作成は、お客様がClaudeのChat・Cowork・Codeを使い分けて自由に行えます。「AIが勝手に全部分析してくれる」のではなく、「SQLなしで深掘りできる環境を、整備された状態で手に入れられる」とイメージしてください。
広告データをSQLなしで分析する環境を、最短で。
インハウスプラスのClaude MCP連携サービスなら、Claude × BigQueryの連携基盤の構築・運用をまるごとお任せできます。閲覧権限の付与だけで最短1営業日から導入でき、BigQueryの費用も込み。Google・Meta・Yahoo!・LINE・Xなど33媒体以上の広告データに対応します。ご利用はサブスク型 Standardプラン(月額14,800円〜・税込)以上から。連携後はChat/Cowork/Codeを使い分けて、分析〜資料作成まで自由に構築できます。
Claude MCP連携サービスの詳細を見るBigQuery MCPを安全に運用するための注意点
結論
BigQuery MCPは「読み取り専用(SELECTのみ・dry-runで検証)」で構成するのが基本です。最小権限のサービスアカウント、対象データセットの限定、BigQueryのクエリ費用の管理という3点を押さえれば、誤操作や情報漏えい・想定外のコストといったリスクを抑えて安全に運用できます。
AIにデータベースをつなぐと聞くと、「勝手にデータを書き換えられないか」「コストが膨らまないか」が気になるはずです。BigQuery MCPは、設計次第でこうしたリスクを十分に抑えられます。順に見ていきましょう。
読み取り専用にする(SELECTのみ・dry-run)
最も重要なのは、読み取り専用で構成することです。代表的なOSSのMCPサーバーは、データを参照する SELECT のみを許可し、INSERT・UPDATE・DELETE といった書き込み・削除の操作を拒否するよう設計されています。
さらに、クエリを実行する前にBigQueryのdry-run(実際には実行せず、内容と処理量を見積もる機能)で検証する仕組みを備えたものもあります。これにより、「AIが誤ってデータを消す」「想定外の重い処理が走る」といった事故を未然に防げます。MCPサーバーを選ぶ際は、この読み取り専用設計になっているかを必ず確認しましょう。
権限とデータ範囲を最小化する
接続に使うサービスアカウントの権限は、必要最小限にとどめます。
- 付与するのは閲覧・ジョブ実行など参照に必要な権限のみとし、編集・削除系は付けない
- アクセスできるデータセットを、分析に必要なものだけに限定する
- 鍵ファイル(JSON)は共有を避け、安全な場所に保管する
こうしておけば、万一の場合でも影響範囲を「特定のデータを読むだけ」に閉じ込められます。複数アカウント・複数事業のデータを扱う場合も、データセットやアカウントの単位でフィルタして、見える範囲をコントロールできます。
BigQueryの費用とデータ更新頻度の考え方
BigQueryは、クエリでスキャンしたデータ量に応じて費用が発生します。AIに何度も大きな集計を頼むと、その分のスキャン費用がかかる点は理解しておきましょう。対象期間やテーブルを絞る、不要に広い集計を避けるといった基本を押さえれば、コストは管理可能な範囲に収まります。
また、分析の前提としてデータの更新頻度も把握しておくと安心です。広告データを連携する一般的な構成では、標準で1日1回・前日分が翌朝までに反映される形が多く、当日のリアルタイム値は未確定になります。「今日の数字がまだ出ない」のは不具合ではなく、こうした更新サイクルによるもの、と理解しておくと現場で混乱しません。
なお、こうした権限設計・費用管理・データ連携の保守を自分たちで担い続けるのが負担に感じる場合は、連携基盤の構築・運用を任せるという選択肢があります。次の章で、自力構築との違いを整理します。
自力構築 vs 連携基盤を任せる──継続運用の現実解
結論
検証目的なら自力構築で十分ですが、チームで毎月安定して使うなら「構築・権限設計・保守運用」が継続的な課題になります。インハウスプラスのClaude MCP連携サービスは、このClaude×BigQueryの連携基盤の構築・運用までを代行し、連携後の分析・資料作成はお客様がClaudeのChat・Cowork・Codeで自由に行えます。
ここまでの手順どおりに進めれば、BigQuery MCPを動かすこと自体は難しくありません。本当の分かれ道は、「一度動かす」のではなく「チームで使い続ける」段階で訪れます。
自力構築で継続的に発生する運用負荷
自力構築は、初期費用を抑えて柔軟に試せる一方、運用フェーズでは次のような作業が継続的に発生します。
- サービスアカウントの鍵・権限の管理と棚卸し
- MCPサーバーのバージョンアップ・障害対応
- 広告媒体のデータをBigQueryへ取り込み続けるための連携・保守
- 分析しやすいようにデータを整える前処理の整備
- 担当者が変わったときの引き継ぎ
検証段階では気にならなかったこれらが、運用に乗せた途端に「誰が面倒を見るのか」という問題になります。特に広告データは媒体が多く、データを安定して溜め続ける部分こそが手間のかかるところです。
連携基盤の構築・運用を任せるという選択(Claude MCP連携サービス)
そこで現実的なのが、連携基盤の構築・運用そのものを任せる方式です。自力構築と比較すると、違いは明確です。
| 観点 | 自力構築 | 連携基盤を任せる(Claude MCP連携サービス) |
|---|---|---|
| 初期構築 | 自分で実装・設定 | おまかせ(閲覧権限の付与など最小限の準備のみ) |
| 権限・保守 | 自分で継続管理 | 構築・運用・保守を代行 |
| 広告データ連携 | 自分で整備 | 33媒体以上に対応した連携を提供 |
| つまずきリスク | 鍵・権限・障害に都度対応 | 運用ごと任せられる |
| 導入スピード | 環境次第 | 閲覧権限の付与だけで最短1営業日 |
| 向いている人 | 検証・自分で制御したい | チームで継続運用したい・分析に集中したい |
インハウスプラスの「Claude MCP連携サービス」が提供するのは、あくまでClaude×BigQueryの連携基盤の構築・運用までです。整備された環境の上で、お客様はClaudeのChat(対話型の深掘り分析)・Cowork(資料作成などの業務自動化)・Code(開発・実装)を使い分けて、分析から実行まで自由に組み立てられます。ご利用はサブスク型のStandardプラン(月額14,800円〜・税込)以上が対象で、BigQueryの費用も含まれます。なお3,000社以上の導入実績を持つのはインハウスプラスの広告レポート自動化ツール全体で、Claude MCP連携サービスはそのStandardプラン以上で利用できる機能です。
分析エージェントの構築まで任せたい場合(AIエージェント開発代行)
「連携基盤だけでなく、月次レポートの自動生成やクリエイティブ制作といった分析エージェントの構築までまとめて任せたい」というニーズもあるでしょう。その場合は、業務要件に合わせて個別に開発するAIエージェント開発代行で対応できます。レポーティング自動化の案件を多数手がけており、個別見積もりで要件に合わせて設計・実装します。
構築・権限・保守はおまかせ、分析はあなたの自由に。
インハウスプラスのClaude MCP連携サービスなら、Claude × BigQueryの連携基盤の構築・運用をまるごと代行。閲覧権限の付与だけで最短1営業日から始められ、BigQuery費用も込みです(サブスク型Standardプラン/月額14,800円〜・税込)。連携後の分析エージェントやスライド自動生成の構築までまとめて依頼したい方は、AIエージェント開発代行(個別見積もり)もご検討ください。
Claude MCP連携サービスの詳細を見るまとめ|BigQuery MCPで「SQLなし分析」をチームの当たり前にする
結論
BigQuery MCPは、MCPという共通規格でClaudeとBigQueryをつなぎ、SQLを書かずに自然言語でデータを分析できるようにする仕組みです。仕組みを理解し、構築方式を選び、接続して、広告分析に活かし、安全に運用し、継続運用は任せるという順で考えれば、迷わず導入を判断できます。
本記事の要点を振り返ります。
- 仕組み:AIがスキーマ確認からSQL生成・実行までを自動化するため、利用者はSQLを書かない
- できること:自然言語で集計・原因究明・ドリルダウン・示唆出しまで、対話で深掘りできる
- 構築方式:①OSS自作 ②フルマネージド(リモート) ③連携基盤を任せる、の3択
- 接続:サービスアカウント+読み取り権限を用意し、設定ファイルにMCPサーバーを登録する
- 広告分析:媒体・クリエイティブ・キーワード・属性・時間帯まで横断し、Markdown/PPTX/Slackに整形できる
- 安全運用:読み取り専用・最小権限・費用管理の3点を押さえる
- 継続運用:チームで使い続けるなら、連携基盤の構築・運用を任せる選択が現実的
まずはリモートMCPサーバーか自力構築で小さく試し、「これは業務に効く」と感じたら、連携基盤を任せて運用に乗せる。この二段構えが、失敗の少ない進め方です。Claude連携やMCPの全体像をあらためて確認したい方は、「Claude MCP総合ガイド」もあわせてご覧ください。
SQLなしのデータ分析を、チームの当たり前に。
広告データをClaudeで分析する環境づくりは、インハウスプラスのClaude MCP連携サービスにおまかせください。Claude × BigQueryの連携基盤の構築・運用を代行し、閲覧権限の付与だけで最短1営業日から導入できます(サブスク型Standardプラン/月額14,800円〜・税込、BigQuery費用込み)。まずはお気軽にご相談ください。
資料請求・お問い合わせはこちらよくある質問(FAQ)
Q1. BigQuery MCPとは何ですか?
MCP(Model Context Protocol)という共通規格でClaudeなどのAIとBigQueryを接続し、SQLを書かずに自然言語でデータを分析できるようにする仕組みです。AIがスキーマの確認からクエリの生成・実行までを自動で行います。
Q2. BigQuery MCPの利用にSQLの知識は必要ですか?
不要です。「先月のCPAは?」のような日本語の依頼でClaudeがSQLを自動生成・実行します。「使ったSQLを見せて」と頼めば、生成されたSQLの内容を確認することもできます。
Q3. BigQuery MCPサーバーはどう用意すればいいですか?
大きく3通りです。①OSS(@ergut/mcp-bigquery-serverなど)を自分で建てる、②GoogleのフルマネージドなリモートMCPサーバーを使う、③連携基盤の構築・運用ごと任せる。手軽さ重視なら②、チームでの継続運用なら③が現実的です。
Q4. BigQuery MCPは安全に使えますか?
読み取り専用(SELECTのみ・dry-runで検証)で構成し、最小権限のサービスアカウントと対象データセットの限定を行えば、誤操作や情報漏えいのリスクを抑えて運用できます。書き込み・削除系の権限は付けないのが基本です。
Q5. 広告データの分析にBigQuery MCPは使えますか?
使えます。広告データをBigQueryに集約すれば、媒体・クリエイティブ・キーワード・ユーザー属性・時間帯まで横断して自然言語で分析でき、結果をMarkdown・PPTX・Slack用テキストに整形できます。インハウスプラスのClaude MCP連携サービスは、この分析を行うためのClaude×BigQueryの連携基盤の構築・運用を提供します(サブスク型Standardプラン以上)。
DeNAのデジタルマーケティング責任者として年間450億円を超えるECプラットフォームのマーケティングを担当。2014年に独立し、上場企業から資金調達後のスタートアップまでさまざまな企業のデジタルマーケティングのプロジェクトに関わり見識を広げた後、2018年3月に株式会社CALLOSUMを創業。